Serialization is the modifying process of a structure of modeling data, made with the purpose of integrating the respective concept into other databases. It is important to find the right format, so the new structure would be fully integrated in the database. The simplest and easiest way of understanding serialization is to take the example of memory buffering, or network connections. A piece of a program is inserted into the memory buffer, with the purpose of integrating the respective structure into another structure later.
This secondary structure could be another program, another computer, or another network node. Serialization is used to create an identical clone with the initial program, and to adapt it to fit into the new structure. However, for complex objects, it is impossible to create the perfect clone, therefore there are secondary methods used to create the clone that fits the secondary system. You will find this process under the name deflating, but it is basically the same process: the procedure of extracting data from a string of binary codes, as a method to describe objects, with the purpose of placing the respective objects into a new compatible structure. It is a method of distributing objects, which is commonly used to improve programs and software, and to create updated versions of the respective codes.
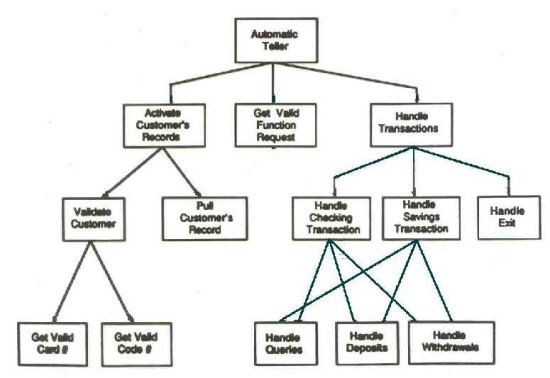
Image Courtesy: csc.calpoly.edu
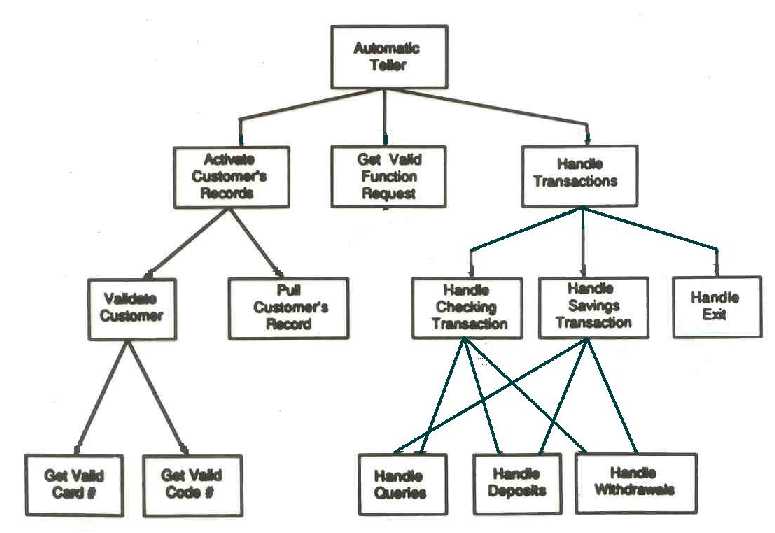
As the business grows in sizes and it also grows in great complexity, most especially when it comes to the organization and the kinds of projects that they undertakes. This increasing complexity simply makes it more difficult to convey the organizational structure of the business and also to manage the elements of the project. The three-stage project that a person could perform simply gives out an essentially different managing challenge than the five-stage project calling out for about 10 employees. The structure charts simply give out a simple and visual solution for this kind of problems.
Right at its core, the persistence of the structure chart is by giving out a basic, graphical picture of a much more complex society or process as well. For instance, in the industry of construction, the structural chart could actually outline how the general manager as well as the director have indirect or direct contact with both of the design departments and engineering, yet the two departments would actually remain to be effectively isolated from each other. This kind of graphical representations would let the viewer to just grasp the basic relationships in between the parts of the company or even with the process without being bogged down in the details.
Do you know what data dictionary is? Well, it is a file defining the basic organization of the database. A data dictionary mainly contains a good list of entire files in the database alone. The number of records on every file as well as the types and the name of every field. Most of the database management systems mainly keep up the data dictionary being hidden from the users in order to prevent it from destroying the entire contents in an accidental manner.
At some point, the database applications could be easily done in a simpler way if you only uphold a body of data reciting your tables. Each of the single programming tasks in the database application has to know something regarding the tables in which it is working with. Thus, every program in the framework and other programs in the application alone could actually benefit from the central information store regarding the database.
Moreover, the term data dictionary is being used by many people. This way, they could denote the separate set of the tables describing the application tables. The data dictionary containing all of this information as the types, column names as well as sizes, yet descriptive information just like the foreign keys, primary keys, titles and the captions for the user interface regarding how to display the field.
Do you know what the generalization and the association are? Well, these terms mainly signify the relationships in between the classes. These are mainly the building blocks of the object oriented programing and a basic material. However, for some, such terms would look like the Greek and the Latin. On the other hand, for you to understand Association as well as Generalization, here are those:
Association
The association is a kind of relationship in between two different objects. In a simple word, the association mainly defined the multiplicity in between the two objects. You could be aware about the one to one, the one to many and, the many to one and the many to many, as it helps in defining the association in between the objects. The aggregation is also a special form of association. The composition is also a special form of aggregation. Thus, they simply correlate with each other.
Generalization
Generalization mainly uses the “Is-A” relationship from the specialization to the class of generalization. The common structure as well as the behavior are being used from the specialization up to the generalized class. At a wider level, you could understand this thing as an inheritance. So, why inheritance, well, this is for the reason that you could relate this term very much.
The procedure of converting the set of object instances containing the references to each to other linear stream of bytes that could be sent throughout the socket, being stored to a certain file or manipulated as the data stream is being known as the Serialization.
The serialization is actually the mechanism being used by the RMI to pass out objects in between the JVMs, either as the arguments in the invocation of the method right from the client into a certain server or as the return values from the invocation of the method. In the primary section of such book, it would be referred to such procedure several times, yet being behind a thorough discussion until today. At this moment, they would then drill down upon the mechanism serialization, by the end of it, you would exactly understand how the serialization actually works and how to efficiently use it within your applications.
On the other hand, the original design of the web, with its connections that are stateless, they mainly serve as a good type of example of the distributed application that could definitely tolerate almost any sort of transient failure of the network. The serialization is the mechanism being built upon the core of the Java libraries for writing a certain group of the objects into the data stream.
It is an expression that recommends to approach an interconnected system of networks that have no wires by persuading the personal computer enclosed by the distance of some other’s connection that does not contain wires and to avail that facility without even the consent or allowance of the customer. It is a lawfully as well as morally a disputatious system or work, together with the rules that deviate in range and authority all over the universe. Whereas it is considered as entirely illegitimate in some areas and allowed in various regions.
The process of retrieving unbarred connection that does not have wires is very easy. The user and clients of a selling area that supplies a lively entertaining spot, just like a café or any motel, it is not usually taken as a piggybacking; although the ones who are not the clients or those who are not inside the building might be included under the act of piggy backing. All these kinds of places supply the internet facilities as an indulgence towards their customers. In order to defend your internet system from piggybacking, make sure that the encoding is activated for your device.
The purpose of hashing is to construct, explore or erase from the record or a table. The main concept or method involved in hashing is to catch a an area or a domain in a document, which is called a key. It transforms the key using a constant procedure into a numerical use, that is named as the hash key. It describes the situation for either keeping or searching a component in the table.
The most frequent way of discovering the hash key is the separation process or technique of hashing. It has a specific formula that makes the processing possible. Under the process, the option of using the hash as well as focusing the dimensions of the table are required to focus on observantly. The users should also make themselves aware of the fact that the keys are not invariably numeric. As a matter of fact, it is usually as a string.
This procedure is mainly a sensible and appropriate policy except for the fact that the key has certain objectionable attributes. The process of hashing includes calculating the location inwardly the orderly arrangement. It also contains numerous fully known activities as well. It is also operated in various encoding algorithms.
It is a synchronized word form which look up towards setting jobs in a shelter, that is a significant portion in a hard disk where an instrument can acquire them whenever it is fully prepared. Spooling is beneficial because different instruments retrieve the information at distinct proportions. The shelter or a buffer supplies a channel of waiting where the information can relax during the time when devices that cause a delay can overtake. The most usual and popular act of applying spooling is ‘print spooling’, in which the written information is transferred into a shelter, or a hard disk and then the printing machine extracts them out of the hard disk at its personal yet special standards. Due to the fact that the information is on a hard disk where it can be retrieved by the printing machine, it is possible for the users to fulfill extra dealings on the computer system, during the time when the process of printing takes place behind the scenes. Spooling also allow its users to put the quantity of occupations that deal with the process of printing on a line rather than being inactive every single time and waiting for them to end up sooner than mentioning the upcoming one.
The process of fragmentation depicts the situation of a disk In which the information is separated into various sectors or parts that are spread all over the disk. It takes place inherently when the disk is used more often while producing, removing or altering the information. Meanwhile, the working system requires to keep the divisions of the documents into a bunch which is not even connected. This is completely hidden from the users. It might also cause a delay in the rapidity in which the information Is acquired, the reason behind it is that the disk drive has to explore the various sectors of the disk in order to set the solitary document simultaneously.
The external fragmentation takes place when the progressive and active designated recollection procedure distributes according to the segments of the space of capacity and the trivial and isolated portion remains back that might not be successfully accustomed. This type of fragmentation happens when the empty space of capacity is separated into various minor groups over a period of time.
Whereas the internal fragmentation is the portion that has been usually deteriorated internally in the designated groups of capacity due to the limitation on the assigned dimensions and proportions of the designated groups.
Semaphores are symbols that assists in conducting admittance to the means that can be used to cope with a difficult situation. There are various kinds of semaphores that are categorized as Binary, Counting and Mutex. The Binary semaphores are accustomed to acquire incompatible admittance to every individual initiative. A numeration semaphore that contains the highest value of 1 is equal to the binary semaphore. Moreover, the Counting semaphores are habituated when you have several inclinations. Whereas the mutex semaphore is made as effective as possible for utilizing in conducting reciprocally incompatible admittance to a device. There are various devices of this kind of semaphore.
Semaphores are basically applied for two reasons which involve it to divide a joint or mutual capacity for recollection and retention as well as to assign admittance to the documents. It is amongst one of the systematic procedures for the interrelated working and transmission. The communication of computer programming supplies a lodge of connections or duties in order to handle semaphores.
It can also be taken as a technique that serves as a means of communication, basically to grant approval in order to move forward or to halt the process. It also contains several additional senses or significance.